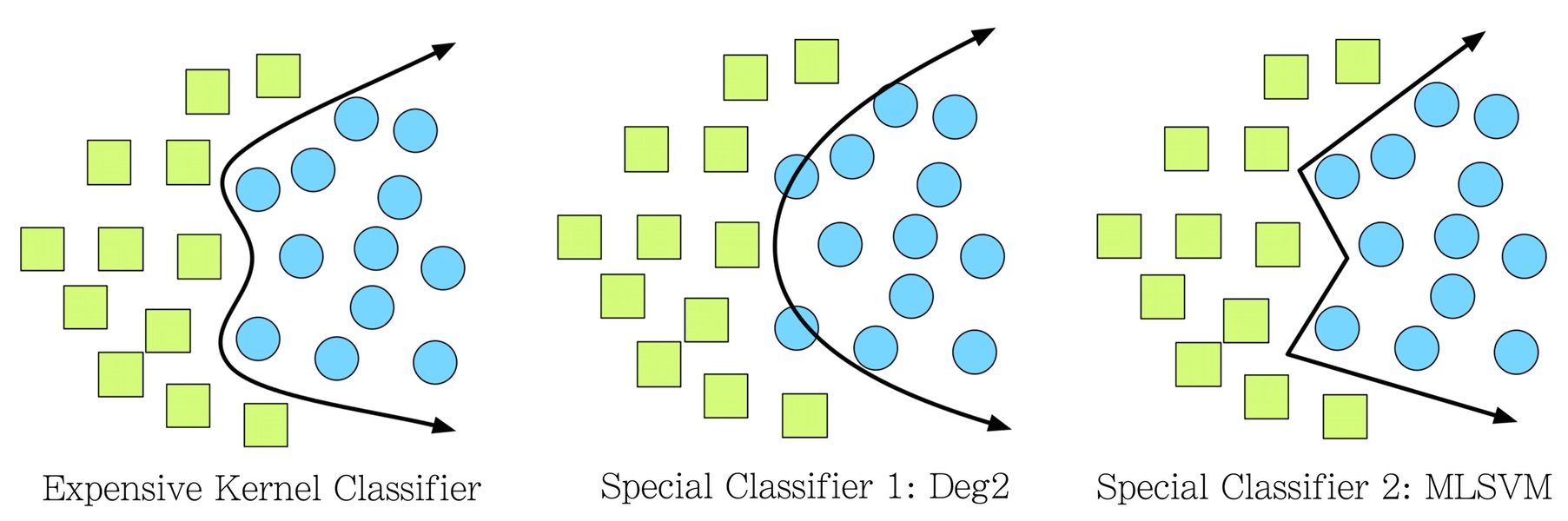
While machine learning is useful in many area, it remains challenging for both experts and non-experts to apply them to a newly encountered problem. In particular, we focus on classification problem where we try to learn an algorithm to classify each feature vectors to a discrete class. One method, called kernel classifier, achieves the best score for most problems, but is extremely slow. Another method, called linear classifier, can sometimes be as good as kernel classifier (while losing for others), but is extremely fast. In this work, we tackle the problem of deciding whether you need to train the bulky kernel classifier when you arrived at a new learning problem.
Finding the solution with a single pass on the data set is extremely difficult. So we propose to make decision by training a special classifier that is efficient and satisfy the same relation with linear classifiers (i.e. if kernel >> linear, then special classifier >> linear; if kernel ~ linear, then special classifier ~ linear). Thus by comparing the relation between the special and the linear classifier, we can predict the behaviour of the expensive kernel classifier. Note that the usefulness of this strategy depends on the efficiency of the special classifier, where our proposed method is able to run in similar time as linear classfier. And has excellent prediction performance when used empirically.
Publication:
H.-Y. Huang, C.-J. Lin. Linear and Kernel Classification: When to Use Which?, SIAM International Conference on Data Mining (SDM 2016).